I am happy to announce two new open access publications in the SENTiVENT project marking the end of my PhD and culminating in my dissertation.
Example of event and sentiment extraction in the SENTiVENT project.
SENTiVENT: enabling supervised information extraction of company-specific events in economic and financial news” has spent a long time in the oven at the Journal Language Resources and Evaluation. Here we describe the construction of fine-grained company-specific events in English economic news articles. The domain of event processing is highly productive and various general domain, fine-grained event extraction corpora are freely available but economically-focused resources are lacking. This work fills a large need for a manually annotated dataset for economic and financial text mining applications. A representative corpus of business news is crawled and an annotation scheme developed with an iteratively refined economic event typology. The annotations are compatible with benchmark datasets (ACE/ERE) so state-of-the-art event extraction systems can be readily applied. This results in a gold-standard dataset annotated with event triggers, participant arguments, event co-reference, and event attributes such as type, subtype, negation, and modality. An adjudicated reference test set is created for use in annotator and system evaluation. Agreement scores are substantial and annotator performance adequate, indicating that the annotation scheme produces consistent event annotations of high quality. In an event detection pilot study using transformer-based deep transfer learning, satisfactory results were obtained with a macro-averaged 𝐹1-score of 59% validating the dataset for machine learning purposes. This dataset thus provides a rich resource on events as training data for supervised machine learning for economic and financial applications. The dataset and related source code is made available at https://osf.io/8jec2/.
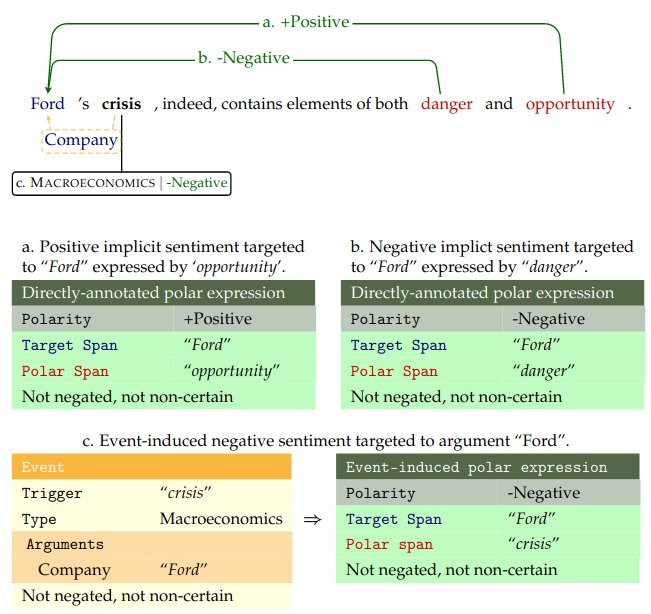
Secondly, we gladly present Fine-Grained Implicit Sentiment in Financial News: Uncovering Hidden Bulls and Bears which enhances the previously created event dataset with investor sentiment annotations. The field of sentiment analysis is currently dominated by the detection of attitudes in lexically explicit texts such as user reviews and social media posts. In objective text genres such as economic news, indirect expressions of sentiment are common. Here, a positive or negative attitude toward an entity must be inferred from connotational or real-world knowledge. To capture all expressions of subjectivity, a need exists for fine-grained resources and approaches for implicit sentiment analysis. We present the SENTiVENT corpus of English business news that contains token-level annotations for target spans, polar spans, and implicit polarity (positive, negative, or neutral investor sentiment, respectively). We both directly annotate polar expressions and induce them from existing schema-based event annotations to obtain event-implied implicit sentiment tuples. This results in a large dataset of 12,400 sentiment–target tuples in 288 fully annotated articles. We validate the created resource with an inter-annotator agreement study and a series of coarse- to fine-grained supervised deep-representation-learning experiments. Agreement scores show that our annotations are of substantial quality. The coarse-grained experiments involve classifying the positive, negative, and neutral polarity of known polar expressions and, in clause-based experiments, the detection of positive, negative, neutral, and no-polarity clauses. The gold coarse-grained experiments obtain decent performance (76% accuracy and 63% macro-F1) and clause-based detection shows decreased performance (65% accuracy and 57% macro-F1) with the confusion of neutral and no-polarity. The coarse-grained results demonstrate the feasibility of implicit polarity classification as operationalized in our dataset. In the fine-grained experiments, we apply the grid tagging scheme unified model for <polar span, target span, polarity> triplet extraction, which obtains state-of-the-art performance on explicit sentiment in user reviews. We observe a drop in performance on our implicit sentiment corpus compared to the explicit benchmark (22% vs. 76% F1). We find that the current models for explicit sentiment are not directly portable to our implicit task: the larger lexical variety within implicit opinion expressions causes lexical data scarcity. We identify common errors and discuss several recommendations for implicit fine-grained sentiment analysis. Data and source code are available at https://osf.io/cbjta/.
On this blog you can find other posts and publications on my PhD research in the SENTiVENT project.